May 19 2026 · Remote Sensing ·
Air QualityQGISPython19 Мая 2026 · Дистанционное зондирование ·
Air QualityQGISPython
Air quality mapping based on Pm2.5 dataКартирование качества воздуха на основе данных Pm2.5
This project focuses on analyzing the spatial distribution of PM₂.₅ concentration in Almaty using open air quality monitoring data for 2025. The workflow consists of two stages: data preprocessing and aggregation in Python, followed by spatial interpolation and map styling in QGIS.
Context
Almaty regularly appears on lists of cities with poor air quality. Fine particulate matter PM₂.₅ — particles smaller than 2.5 micrometers in diameter — poses a particular health risk. Due to their size, these particles penetrate deep into the lungs and enter the bloodstream. The WHO annual guideline is 5 µg/m³ — for reference, none of the monitoring stations in Almaty meets this standard.
Part 1 — Data Preprocessing in Python
Data Source
The monitoring data comes from the open dataset Almaty Air Quality History on Kaggle. It contains hourly PM₂.₅ concentration readings from several dozen stations across the city. Download the CSV and place it in the same directory as the script.
Cleaning and Aggregation
The script filters data for 2025 only and retains readings from two reliable providers — Clarity and AirNow. An upper threshold of 500 µg/m³ is applied to exclude obvious sensor malfunctions without affecting real peak values. Stations with fewer than 1000 measurements for the year are excluded, as their annual averages are unreliable. The output is a CSV with one row per station: name, coordinates, annual mean PM₂.₅, and observation count.
Place air_quality_data.csv in the same directory as the script
Run the script — it will output station_means.csv
⚠ Anomalous stations: Some stations show extremely high annual mean values (>200 µg/m³) due to incomplete coverage — they were only active during the winter peak. The provider filter and the 500 µg/m³ threshold eliminate most such cases, but if needed, the upper limit can be further reduced to 200 µg/m³.
Part 2 — Interpolation and Visualization in QGIS
Importing Station Points
Load station_means.csv into QGIS via Layer → Add Layer → Add Delimited Text Layer. Set X = lon, Y = lat, coordinate system — EPSG:4326. Each point represents a monitoring station with its annual mean PM₂.₅ value.
Station points after CSV import
IDW Interpolation
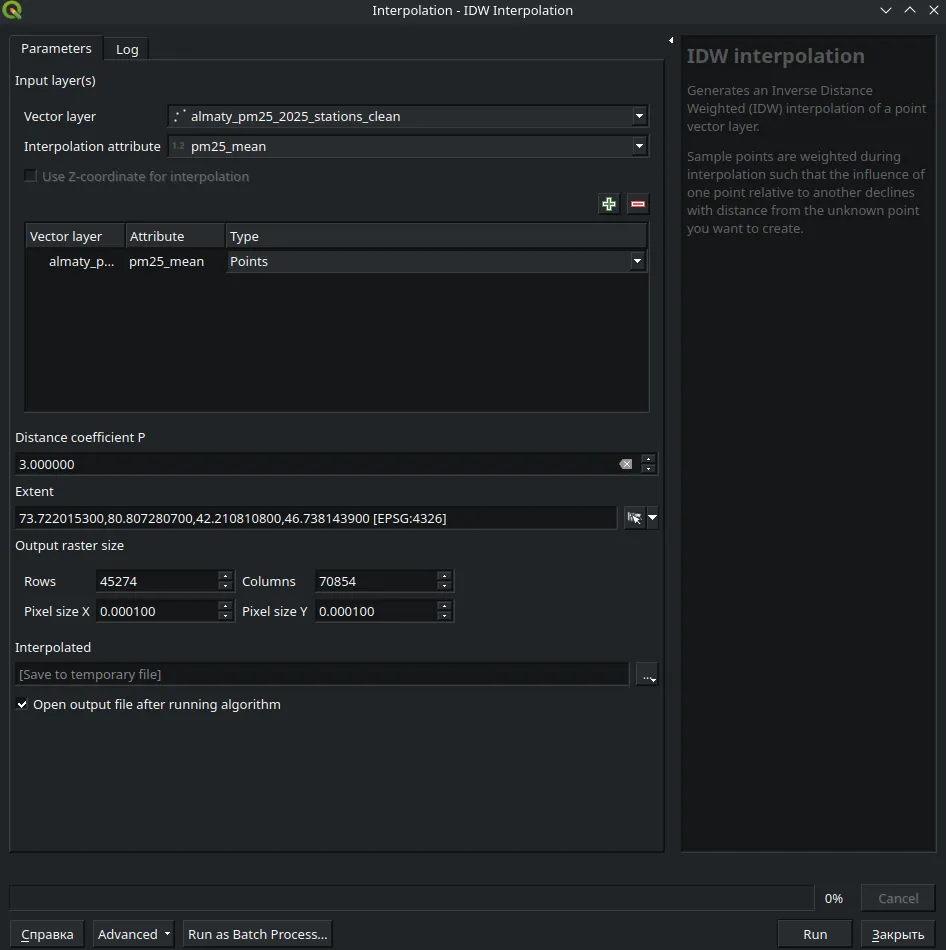
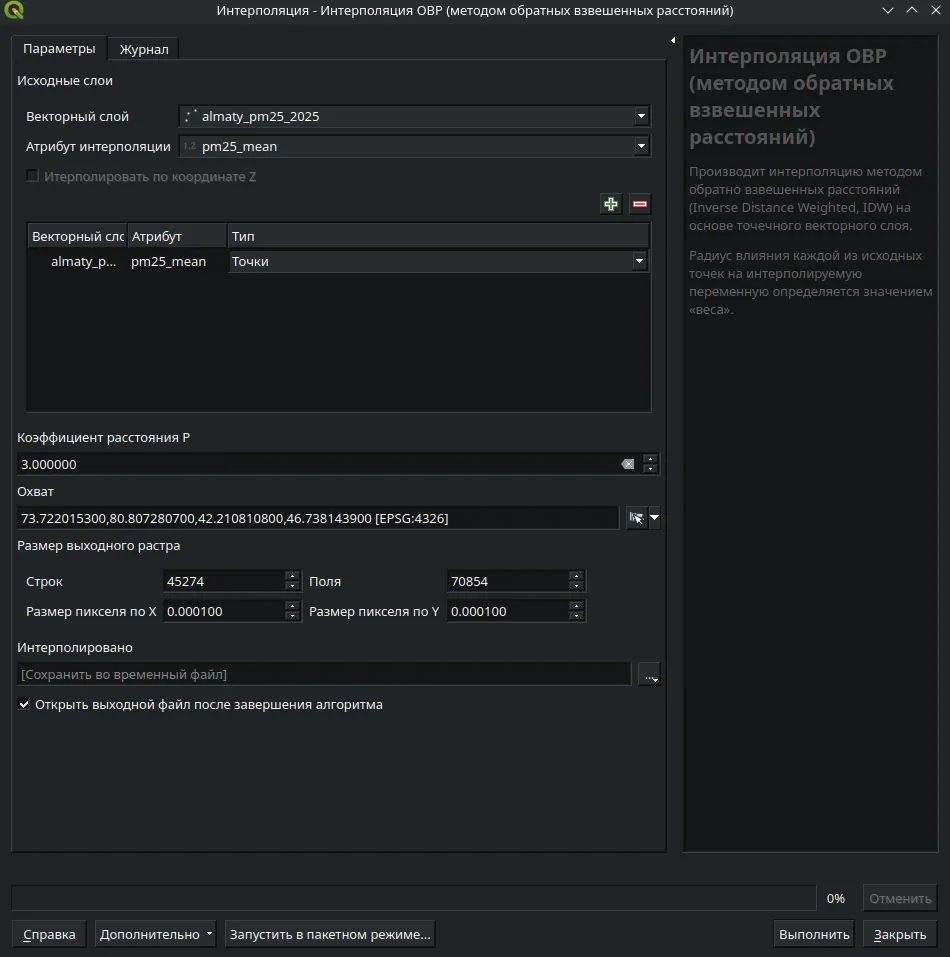
Open Analysis → Toolbox → Search for IDW. In the "Vector layer" field select the station layer; in the "Interpolation attribute" field choose pm25_mean. Set the output raster resolution — the smaller the X and Y pixel size, the higher the quality — and limit the extent to the city's administrative boundary. Click Run — the output will be a raster with a continuous pollution surface.
⚠ Edge effects: IDW stretches toward the values of edge stations and produces artifacts at boundaries. Clip the raster to the administrative boundary via Raster → Extraction → Clip Raster by Mask Layer.
Raster Style Settings
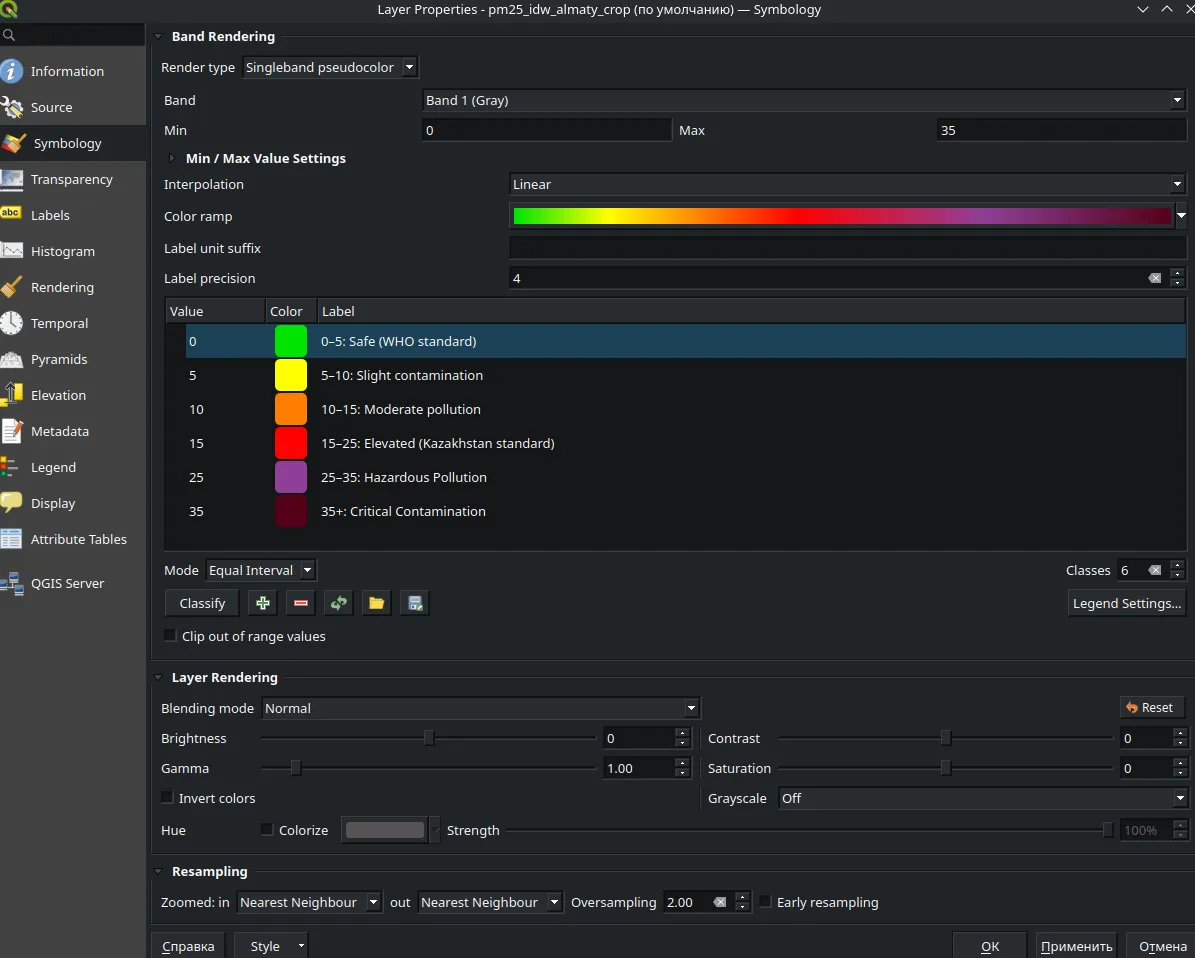
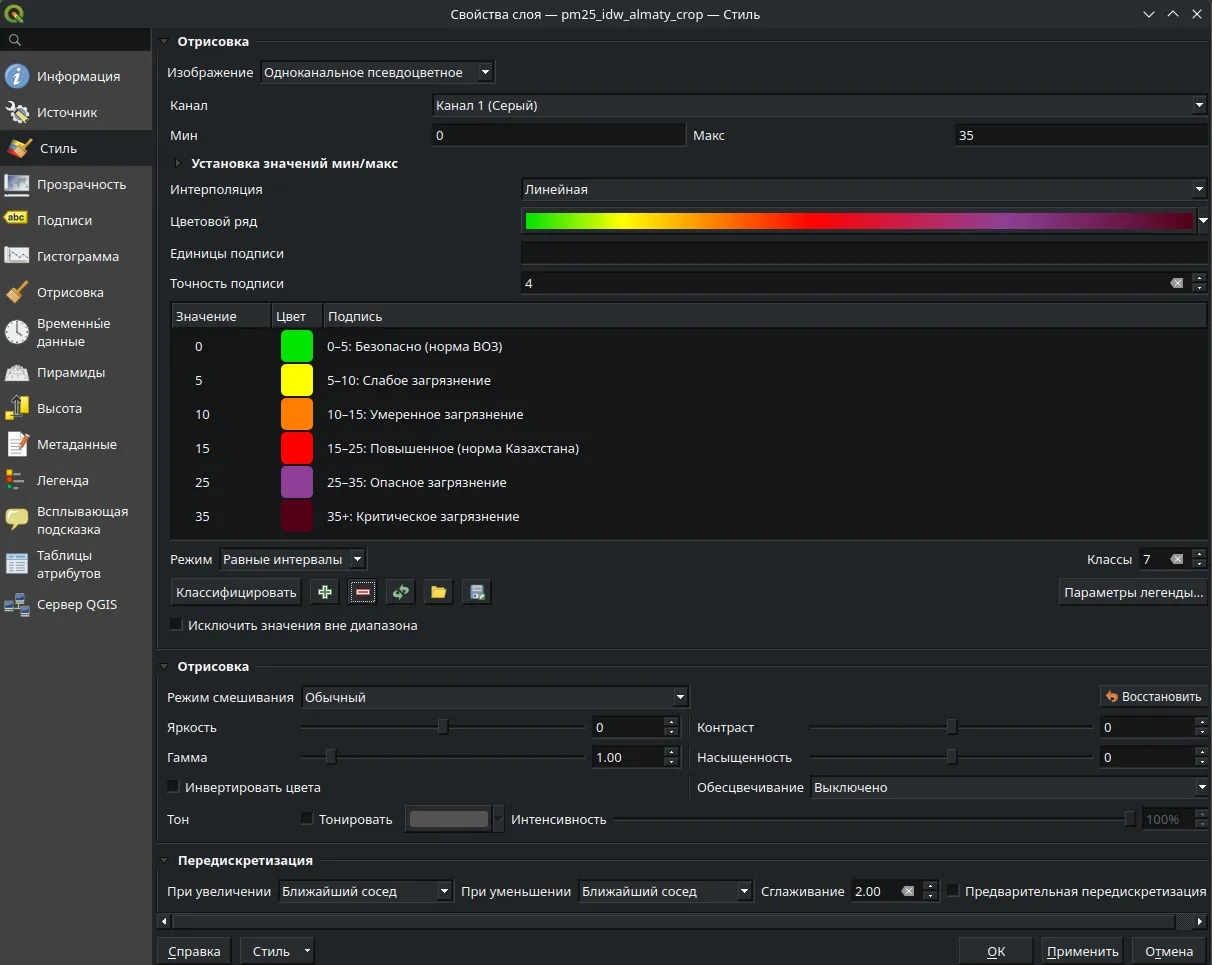
Right-click the layer → Layer Properties → Symbology. Switch the render type to Singleband pseudocolor. Apply the same color ramp as shown in the example:
Symbology settings: singleband pseudocolor.
Final Layout
Add a basemap of your choice beneath the raster layer for context. In the print layout (Project → New Print Layout) add a scale bar, north arrow, PM₂.₅ color scale legend, and a title. Export to PNG or PDF to produce the final map.
Results
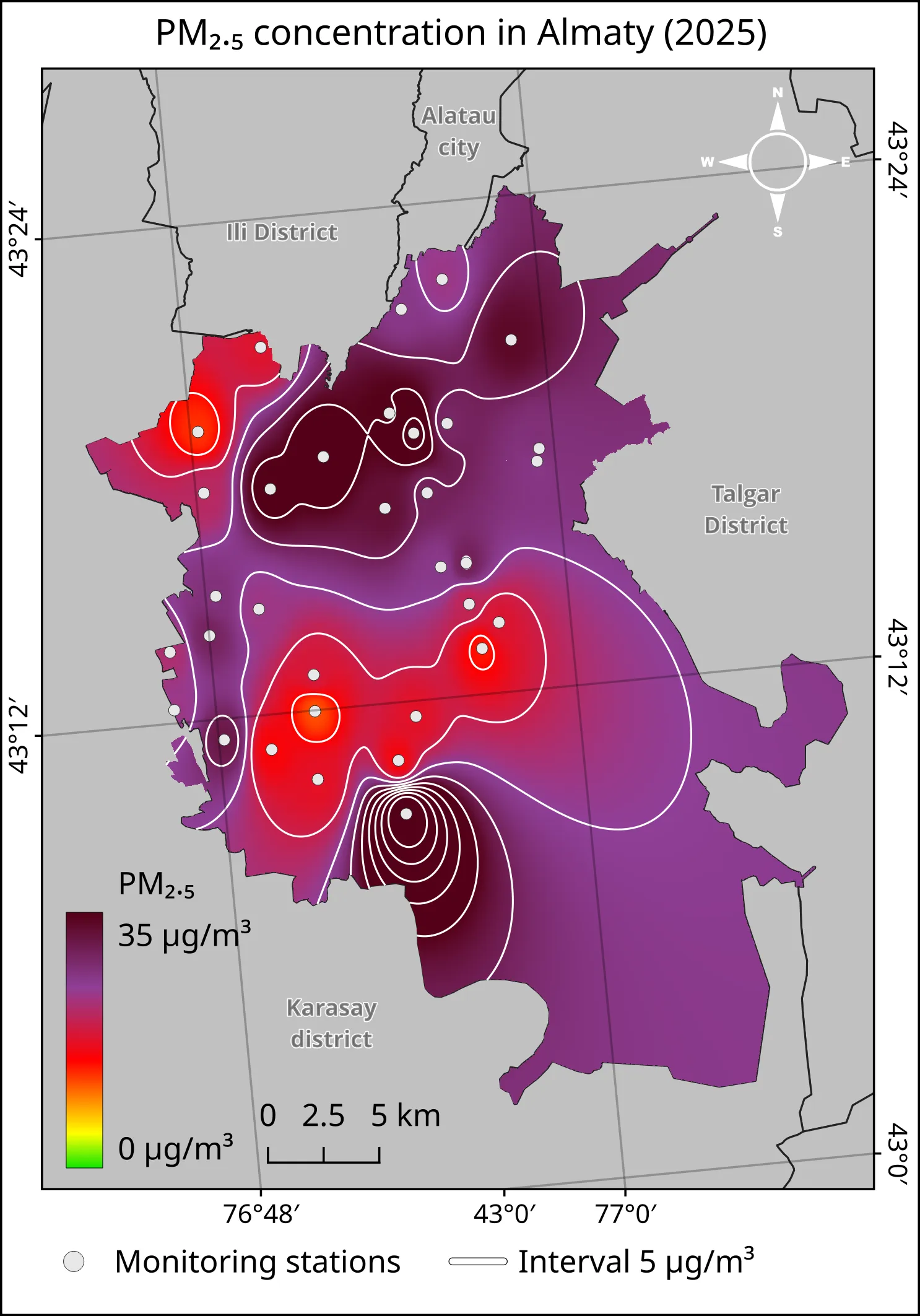
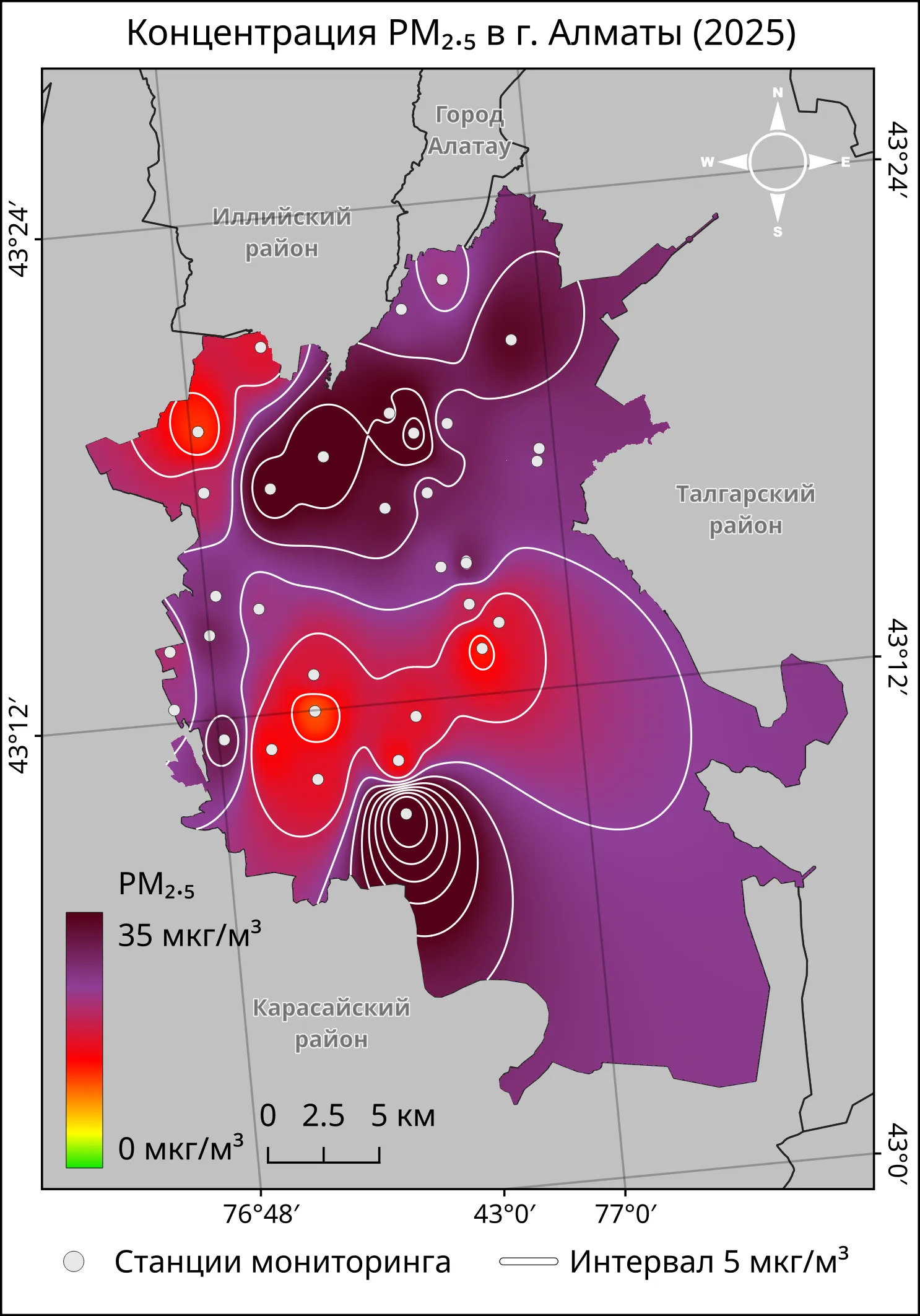
The map below shows the annual mean distribution of PM₂.₅ concentration across Almaty for 2025. The surface was generated using IDW interpolation in QGIS from data collected at 33 monitoring stations.
Conclusion
Open monitoring data combined with Python and QGIS makes it possible to quickly produce a clear air pollution map without expensive equipment. The workflow is easy to reproduce for any other city and any pollutant, as long as point measurements with coordinates are available.
Этот проект посвящён анализу пространственного распределения концентрации PM₂.₅ в Алматы на основе открытых данных мониторинга качества воздуха за 2025 год. Рабочий процесс состоит из двух этапов: предобработка и агрегация данных в Python, затем пространственная интерполяция и оформление карты в QGIS.
Контекст
Алматы регулярно попадает в списки городов с неблагоприятным качеством воздуха. Особую опасность представляют мелкодисперсные частицы PM₂.₅ — диаметром менее 2,5 микрометра. Из-за своего размера они беспрепятственно проникают в лёгкие и попадают в кровоток. Норма ВОЗ составляет 5 мкг/м³ в год — для сравнения, ни одна из станций мониторинга в Алматы этому стандарту не соответствует.
Часть 1 — Предобработка данных в Python
Источник данных
Данные мониторинга — открытый датасет Almaty Air Quality History на платформе Kaggle. Это почасовые замеры концентрации PM₂.₅ с нескольких десятков станций по всему городу. Скачайте CSV и сохраните рядом со скриптом.
Очистка и агрегация
Скрипт фильтрует данные только за 2025 год и оставляет показания только двух надёжных провайдеров — Clarity и AirNow. Дополнительно задаётся жёсткий верхний порог в 500 мкг/м³ — он отсекает явные технические сбои датчиков, не затрагивая реальные пиковые значения. Станции с охватом менее 1000 измерений за год исключаются — их среднегодовое значение ненадёжно. На выходе получается CSV с одной строкой на станцию: название, координаты, среднегодовое PM₂.₅ и количество измерений.
import pandas as pd
df = pd.read_csv('air_quality_data.csv',
usecols=['datetime', 'location_id', 'pm25', 'name', 'lat', 'lon', 'provider_name'])
df.rename(columns={'name': 'station', 'location_id': 'station_id'}, inplace=True)
# Только 2025 год
df['datetime'] = pd.to_datetime(df['datetime'], utc=True)
df = df[df['datetime'].dt.year == 2025]
# Только надёжные провайдеры
df = df[df['provider_name'].isin(['Clarity', 'AirNow'])]
df.drop_duplicates(inplace=True)
df.dropna(subset=['pm25', 'lat', 'lon'], inplace=True)
# Убираем физически невозможные значения и технические сбои
df = df[(df['pm25'] > 0) & (df['pm25'] < 500)]
# Оставляем только станции с >= 1000 измерений
counts = df.groupby('station_id')['pm25'].count()
df = df[df['station_id'].isin(counts[counts >= 1000].index)]
# Среднегодовые значения по каждой станции
station_means = df.groupby('station_id').agg(
name=('station', 'first'),
lat=('lat', 'first'),
lon=('lon', 'first'),
pm25_mean=('pm25', 'mean'),
n_observations=('pm25', 'count'),
provider_name=('provider_name', 'first')
).reset_index(drop=True)
station_means.to_csv('station_means.csv', index=False)
print(station_means.sort_values('pm25_mean', ascending=False).to_string())
Как запустить
Установите зависимости: pip install pandas
Положите air_quality_data.csv рядом со скриптом
Запустите скрипт — на выходе получите station_means.csv
⚠ Аномальные станции: Некоторые станции показывают экстремально высокие среднегодовые значения (>200 мкг/м³) из-за неполного охвата — они работали только в зимний пик. Фильтр по провайдеру и порогу 500 мкг/м³ отсекает большинство таких случаев, но при необходимости можно дополнительно ограничить верхний порог до 200 мкг/м³.
Часть 2 — Интерполяция и визуализация в QGIS
Импорт точек станций
Загрузите station_means.csv в QGIS через Слой → Добавить слой → Добавить слой из текстового файла с разделителями. Укажите столбцы X = lon, Y = lat, система координат — EPSG:4326. Каждая точка — это станция мониторинга со среднегодовым значением PM₂.₅.
Точки станций после импорта CSV
IDW-интерполяция
Откройте Анализ → Панель инструментов → Введите в поиске IDW. В поле «Векторный слой» выберите слой станций, в поле «Атрибут интерполяции» — pm25_mean. Задайте разрешение выходного растра, чем меньше размер пикселя X и Y тем качественнее изображение и ограничьте область административной границей города изменив охват. Нажмите Выполнить — на выходе получится растр с непрерывной поверхностью загрязнения.
Настройки инструмента интерполяции: слой, атрибут pm25_mean, метод IDW
⚠ Краевые эффекты: IDW вытягивается к значениям крайних станций и даёт артефакты на границах. Обрежьте растр по административной границе через Растр → Экстракция → Обрезать растр по маске.
Настройка стиля растра
Правая кнопка по слою → Свойства слоя → Стиль. Переключите тип рендера на Одноканальное псевдоцветное. Назначьте такую же цветовую шкалу как в примере:
Настройки стиля: одноканальное псевдоцветное.
Финальное оформление
Добавьте подложку которая вам нравится под слой растра для контекста. В макете печати (Проект → Создать макет) добавьте масштабную линейку, стрелку севера, легенду с цветовой шкалой PM₂.₅ и заголовок. Экспортируйте в PNG или PDF для получения готовой карты.
Результаты
Карта ниже показывает среднегодовое распределение концентрации PM₂.₅ по территории Алматы за 2025 год. Поверхность получена методом IDW-интерполяции в QGIS по данным 33 станций мониторинга.
Заключение
Открытые данные мониторинга в связке с Python и QGIS позволяют быстро получить наглядную карту загрязнения воздуха без дорогостоящего оборудования. Рабочий процесс легко воспроизвести для любого другого города и любого загрязнителя при наличии точечных измерений с координатами.